📂 프로젝트/◾ PAPERS
[AlexNet] 논문 리뷰 및 구현 (코드 설명 포함)
이 정규
2023. 2. 8. 11:23
728x90
반응형
AlexNet
Description:
- AlexNet 특징:
- AlexNet Architecture
- Convolutional layers = 5
- Fully Connected layers = 3
- GPU를 2개의 병렬 구조로 처음 활용
- Activation Function : ReLU 함수를 모든 convolution layer와 fully-connected에 적용 (tanh함수 보다 더 낮은 error 보여줌)
- Max-Pooling Layer : 이전에는 Average Pooling 적용
- kernel size = 3x3
- stride = 2
- number of Max-Pooling layer = 3
- Dropout: over-fitting 방지
- 1, 2 번째 fully-connected layer에 적용
- dropout rate = 0.5
- LRN(local response normalization):
- ReLU 함수가 매우 높은 픽셀을 그대로 받아서 주변에 영향을 미칠 수 있음
- 주변에 영향을 주는 것을 방지해주기 위해 같은 위치에 있는 픽셀끼리 정규화
- 1, 2 번째 convolution layer와 ReLU 뒤에 적용 (k = 2, n = 5, α = 10−4, β = 0.75 )
- LRN layer가 메모리 점유율과 계산 복잡도를 증대시 킬 수 있음 (모델 용량 증대)
- 정규화에 도움 (error 감소)
- 측면 억제를 보여주는 대표적인 사례
- Hermann Grid

- 검은 사각형 안에 흰색의 선이 지나가는 구조로 검은 사각형을 집중해서 볼 때, 측면에 회색 점이 보임
- 반대로 흰색의 선에 집중하면 회색 점이 보이지 않음
- 흰색으로 둘러싸인 측면에서 억제를 발생시키기 때문, 그 결과 흰색이 더 반감되어 보임
- Weight and Bias initialization (convolution layer and Fully connected layer):
- 표준편차(STD)를 0.01로 하는 Zero-mean Gaussian 정규 분포를 활용해 모든 레이어의 weight 초기화
- neuron bias: 2, 4, 5번째 convolution 레이어와, fully-connected 레이어에 상수 1로 적용하고 나머지 레이어는 0을 적용
- Hyperparameter:
- optimizer: SGD -> Adam으로 변경
- momentum: 0.9
- weight decay: 5e-4
- batch size: 128
- learning rate: 0.01 -> 0.0001로 변경
- epoch : 90 -> 10
- adjust learning rate: validation error가 현재 lr로 더 이상 개선 안되면 lr을 10으로 나눠준다
- Image preprocessing:
- Input image shape = 224x224x3
- resize = 256x256
- center crop = 227
- Mean subtraction of RGB per channel
- Dataset:
- 논문: ImageNet Large Scale Visual Recognition Challenge (ILSVRC) - 2012
- 구현: CIFAR10
- System Environment:
- Google Colab Pro

Reference:
- https://bskyvision.com/entry/CNN-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98%EB%93%A4-AlexNet%EC%9D%98-%EA%B5%AC%EC%A1%B0
- https://unerue.github.io/computer-vision/classifier-alexnet.html
- https://roytravel.tistory.com/336
- https://bskyvision.com/421
- https://sensibilityit.tistory.com/512
- https://mathworld.wolfram.com/HermannGridIllusion.html
- Hermann L (1870). "Eine Erscheinung simultanen Contrastes". Pflügers Archiv für die gesamte Physiologie. 3: 13–15. doi:10.1007/BF01855743.
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Communications of the ACM 60.6 (2017): 84-90.
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
Load Modules
# Utils
import numpy as np
import matplotlib.pyplot as plt
# Torch
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from torchvision import transforms
import torchvision
from torchvision.utils import make_grid
# TensorBoard
from torch.utils.tensorboard import SummaryWriter
! pip install tensorboardX
from tensorboardX import SummaryWriterSet Hyperparameters
batch_size = 128
num_epochs = 10
learning_rate = 0.0001Load Data - CIFAR10
train_set = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True, transform=transforms.ToTensor())
test_set = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True, transform=transforms.ToTensor())Visualization
dataiter = iter(train_set)
images, labels = next(dataiter)
img = make_grid(images, padding=0)
npimg = img.numpy()
plt.figure(figsize=(5, 7))
plt.imshow(np.transpose(npimg, (1,2,0)))
plt.show()
Mean subtraction of RGB per channel
train_meanRGB = [np.mean(x.numpy(), axis=(1,2)) for x, _ in train_set]
train_stdRGB = [np.std(x.numpy(), axis=(1,2)) for x, _ in train_set]
train_meanR = np.mean([m[0] for m in train_meanRGB])
train_meanG = np.mean([m[1] for m in train_meanRGB])
train_meanB = np.mean([m[2] for m in train_meanRGB])
train_stdR = np.mean([s[0] for s in train_stdRGB])
train_stdG = np.mean([s[1] for s in train_stdRGB])
train_stdB = np.mean([s[2] for s in train_stdRGB])
print(train_meanR, train_meanG, train_meanB)
print(train_stdR, train_stdG, train_stdB)
Define the image transformation for data
train_transformer = transforms.Compose([transforms.Resize((256,256)),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize(mean=[train_meanR, train_meanG, train_meanB], std=[train_stdR, train_stdG, train_stdB])])
train_set.transform = train_transformer
test_set.transform = train_transformerDefine DataLoader
trainloader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=True, num_workers=2)Create AlexNet Model
class AlexNet(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(in_features=256 * 6 * 6, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=10),
nn.LogSoftmax(dim=1)
)
self.apply(self._init_weight_bias)
def _init_weight_bias(self, module):
classname = module.__class__.__name__
if classname == 'Conv2d':
nn.init.normal_(module.weight, mean=0.0, std=0.01)
nn.init.constant_(module.bias, 0)
if (module.in_channels == 96 or module.in_channels == 384):
nn.init.constant_(module.bias, 1)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return xSet Device and Model
use_cuda = torch.cuda.is_available()
print("use_cuda : ", use_cuda)
FloatTensor = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
device = torch.device("cuda:0" if use_cuda else "cpu")
net = AlexNet().to(device)
X = torch.randn(size=(1,3,227,227)).type(FloatTensor)
print(net(X))
print(summary(net, (3,227,227)))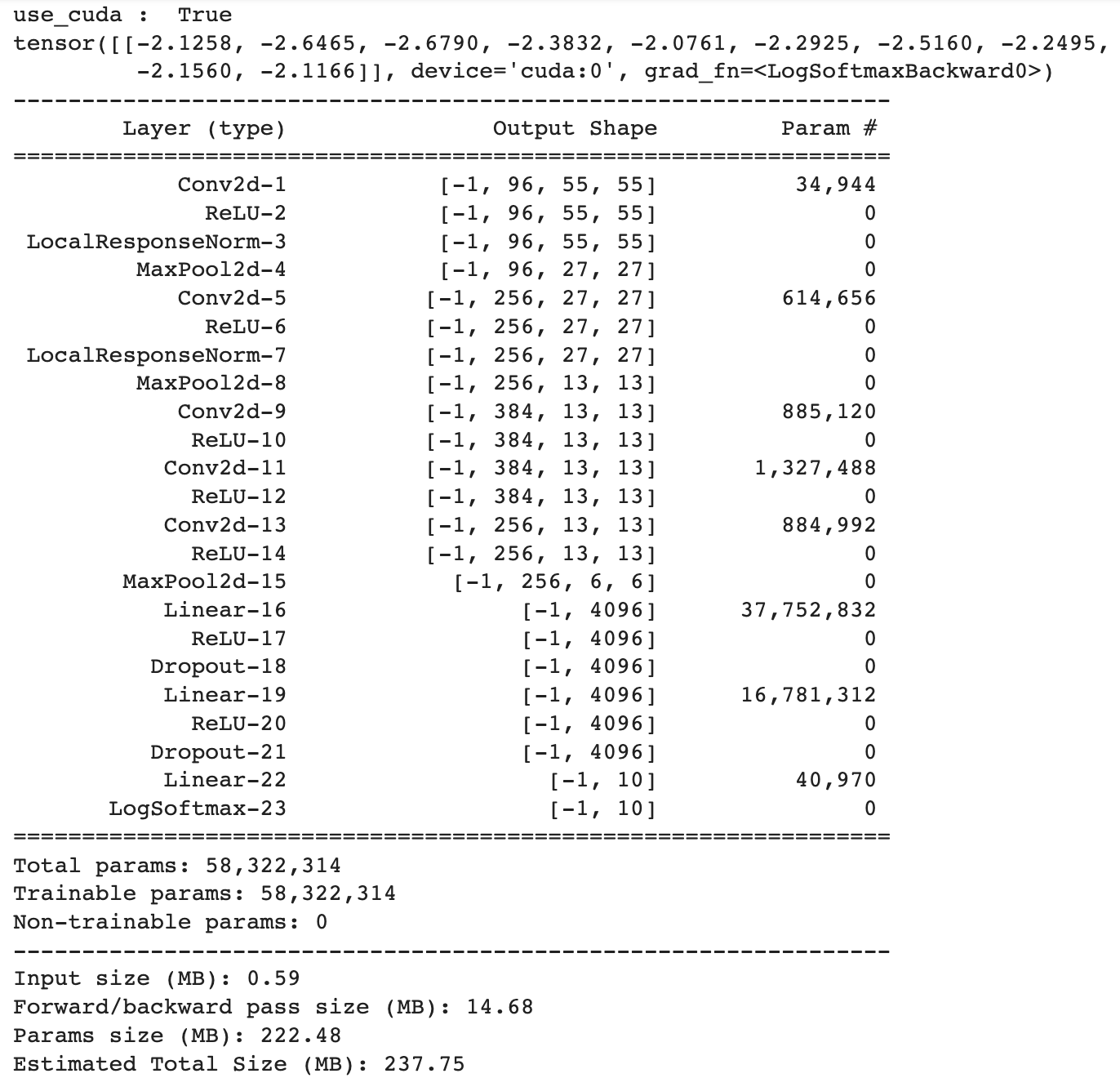
Loss and Optimizer
use_cuda = torch.cuda.is_available()
print("use_cuda : ", use_cuda)
device = torch.device("cuda:0" if use_cuda else "cpu")
model = AlexNet().to(device)
criterion = F.nll_loss
optimizer = torch.optim.Adam(params=model.parameters(), lr=learning_rate)Training Loop
writer = SummaryWriter("./alexnet/tensorboard")
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data,target) in enumerate(train_loader):
target = target.type(torch.LongTensor)
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 30 == 0:
print(f"{batch_idx*len(data)}/{len(train_loader.dataset)}")
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target, reduction='mean').item()
writer.add_scalar("Test Loss", test_loss, epoch)
pred = output.argmax(1)
correct += float((pred == target).sum())
writer.add_scalar("Test Accuracy", correct, epoch)
test_loss /= len(test_loader.dataset)
correct /= len(test_loader.dataset)
return test_loss, correct
writer.close()Per-Epoch Activity
from tqdm import tqdm
for epoch in tqdm(range(1, num_epochs + 1)):
train(model, device, trainloader, optimizer, epoch)
test_loss, test_accuracy = test(model, device, testloader)
writer.add_scalar("Test Loss", test_loss, epoch)
writer.add_scalar("Test Accuracy", test_accuracy, epoch)
print(f"Processing Result = Epoch : {epoch} Loss : {test_loss} Accuracy : {test_accuracy}")
writer.close()
Result
print(f"Result of AlexNet = Epoch:{epoch} Loss:{test_loss} Accuracy:{test_accuracy}")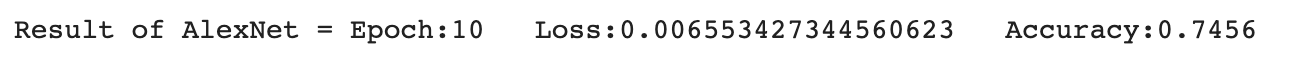
Visualization
%load_ext tensorboard
%tensorboard --logdir=./alexnet/tensorboard --port=6006

728x90
반응형