📂 프로젝트/◾ PAPERS
[GoogleNet] 논문 리뷰 및 구현 (코드 설명 포함)
이 정규
2023. 2. 8. 13:54
728x90
반응형
GoogleNet
Description
- GoogleNet의 특징:
- GoogleNet Architecture:

- GoogLeNet은 네트워크의 depth와 width를 늘리면서도 내부적으로 Inception Module을 활용해 computational efficiency를 확보함
- 이전에 나온 VGGNet이 깊은 네트워크로 AlexNet보다 높은 성능을 얻었지만, 파라미터 측면에서 효율적이지 못하다는점을 보완하기 위해 만듬
- Things to discuss about issues:
- 네트워크의 성능을 올리는 가장 직접적인 방법은 depth, width같은 size를 증대 할 수 있다
- 모델의 층이 깊어질수록 성능은 향상 됨
- 하지만 계산해야 할 연산량이 늘어나 overfitting할 가능성이 증가
- RAM을 너무나 많이 사용해 시간이 오래걸리는 비효율성 발생
- Solution:
- 적은 연산량을 가지고 효율적으로 모델의 특징을 추출하는 방법 고안
- Sparse Connection - fully connected 를 sparsely connected architecture로 변경
- Inception Module - 3개의 inception blocks (3a,3b), (4a~4e), (5a,5b), 총 9개의 inception modules
- Auxiliary Classifier - gradient vanishing 문제 해결 위해 2개의 auxiliary classifier 추가,
- Global Average Pooling(GAP):

- patch size = 7x7
- stride = 1
- global average pooling은 전 층에서 산출된 특성맵들을 각각 평균냄
- 이후 이어서 1차원 벡터를 만듬
- why? 1차원 벡터로 만들어야만 최종적으로 이미지 분류를 위한 softmax 층을 연결함
- 가장 큰 이유는 finetuning의 용이성을 위함
- Max Pooling:
- patch size = 3x3
- stride = 2
- number of max pooling = 4
- Inception Module:
- 1x1 Convolution: kernel_size=1, stride= 1, padding=0
- 3x3 Convolution: kernel_size=3, stride= 1, padding=1
- 5x5 Convolution: kernel_size=5, stride= 1, pading=2
- Max-Pooling: kernel_size=3, stride=1, padding=1
- Auxiliary Classifier:
- 1x1 convolution output channel = 128 적용
- dropout rate = 0.7 적용
- uxiliary Classifier의 input dimensioin = aux1(512), aux2(528)
- Fully Connected Layer(FC Layer):
- 1개의 1024 channel
- Softmax
- Augmentation:
- Input image shape = 224x224x3
- resize = 227x227
- Mean subtraction of RGB per channel
- Hyperparameter
- Optimizer = SGD -> Adam으로 변경
- Momentum = 0.9
- Batch size = 64 -> 128 변경
- learning rate = learning rate scheduler 사용 -> 0.0001으로 변경
- Epoch = not mentioned -> 20 적용
- Dropout = 0.4(FC layer)
- Dataset
- 논문 : ImageNet Large Scale Visual Recognition Challenge(ILSVRC)-2014
- 구현 : CIFAR-10
- System Environment:
- Google Colab Pro
- Google Colab Pro
Reference
- https://roytravel.tistory.com/338
- https://technical-support.tistory.com/87
- https://blog.naver.com/paragonyun/222914679046
- https://github.com/paragonyun/Papers_I_must_read/tree/main/GoogLeNet
- https://bskyvision.com/entry/CNN-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98%EB%93%A4-GoogLeNetinception-v1%EC%9D%98-%EA%B5%AC%EC%A1%B0
- https://d2l.ai/chapter_convolutional-modern/googlenet.html
- https://inhovation97.tistory.com/45?category=920765
- https://teddylee777.github.io/python/inception-module
- C. Szegedy et al., "Going deeper with convolutions," 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 2015, pp. 1-9, doi: 10.1109/CVPR.2015.7298594.
https://arxiv.org/pdf/1409.4842.pdf
Load Modules
# Utils
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
# Torch
import torch
import torch.nn as nn
from torch import Tensor
from typing import Optional
import torch.nn.functional as F
from torchsummary import summary
from torchvision import transforms
import torchvision
# TensorBoard
from torch.utils.tensorboard import SummaryWriter
! pip install tensorboardX
from tensorboardX import SummaryWriterSet Hyperparameters
batch_size = 128
num_epochs = 20
learning_rate = 0.0001Load Data - CIFAR10
train_set = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True, transform=transforms.ToTensor())
test_set = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True, transform=transforms.ToTensor())Mean subtraction of RGB per channel
train_meanRGB = [np.mean(x.numpy(), axis=(1,2)) for x, _ in train_set]
train_stdRGB = [np.std(x.numpy(), axis=(1,2)) for x, _ in train_set]
train_meanR = np.mean([m[0] for m in train_meanRGB])
train_meanG = np.mean([m[1] for m in train_meanRGB])
train_meanB = np.mean([m[2] for m in train_meanRGB])
train_stdR = np.mean([s[0] for s in train_stdRGB])
train_stdG = np.mean([s[1] for s in train_stdRGB])
train_stdB = np.mean([s[2] for s in train_stdRGB])
print(train_meanR, train_meanG, train_meanB)
print(train_stdR, train_stdG, train_stdB)
Define the image transformation for data
train_transformer = transforms.Compose([transforms.Resize((227,227)),
transforms.ToTensor(),
transforms.Normalize(mean=[train_meanR, train_meanG, train_meanB], std=[train_stdR, train_stdG, train_stdB])])
train_set.transform = train_transformer
test_set.transform = train_transformerDefine DataLoader
trainloader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=True, num_workers=2)Created GoogleNet Model
- Convolutional Block
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x- Inception Modules
class Inception(nn.Module):
def __init__(self, in_channels, n1, n3_reduce, n3, n5_reduce, n5, pool_proj):
super().__init__()
self.branch1 = ConvBlock(in_channels, n1, kernel_size=1, stride=1, padding=0)
self.branch2 = nn.Sequential(
ConvBlock(in_channels, n3_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n3_reduce, n3, kernel_size=3, stride=1, padding=1)
)
self.branch3 = nn.Sequential(
ConvBlock(in_channels, n5_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n5_reduce, n5, kernel_size=5, stride=1, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
ConvBlock(in_channels, pool_proj, kernel_size=1, stride=1, padding=0)
)
def forward(self, x):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim=1)- Auxiliary classifier
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.avg_conv = nn.Sequential(
nn.AvgPool2d(kernel_size=5, stride=3),
ConvBlock(in_channels, 128, kernel_size=1, stride=1, padding=0)
)
self.fc = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(),
nn.Dropout(p=0.7),
nn.Linear(1024, num_classes)
)
def forward(self, x):
x = self.avg_conv(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return xclass GoogLeNet(nn.Module):
def __init__(self, aux_logits=True, num_classes=10):
super().__init__()
self.aux_logits = aux_logits
self.conv1 = ConvBlock(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.conv2 = ConvBlock(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0)
self.conv3 = ConvBlock(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(kernel_size=8, stride=1)
self.dropout = nn.Dropout(p=0.4)
self.linear = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = None
self.aux2 = None
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool3(x)
x = self.a4(x)
aux1 = None
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
aux2 = None
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.e4(x)
x = self.maxpool4(x)
x = self.a5(x)
x = self.b5(x)
x = self.avgpool(x)
x = x.view(x.shape[0], -1)
x = self.linear(x)
x = self.dropout(x)
if self.aux_logits and self.training:
return [x, aux1, aux2]
else:
return xSet Device and Model
use_cuda = torch.cuda.is_available()
print("use_cuda : ", use_cuda)
FloatTensor = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
device = torch.device("cuda:0" if use_cuda else "cpu")
net = GoogLeNet().to(device)
X = torch.randn(size=(3,227,227)).type(FloatTensor)
print(summary(net, (3,227,227)))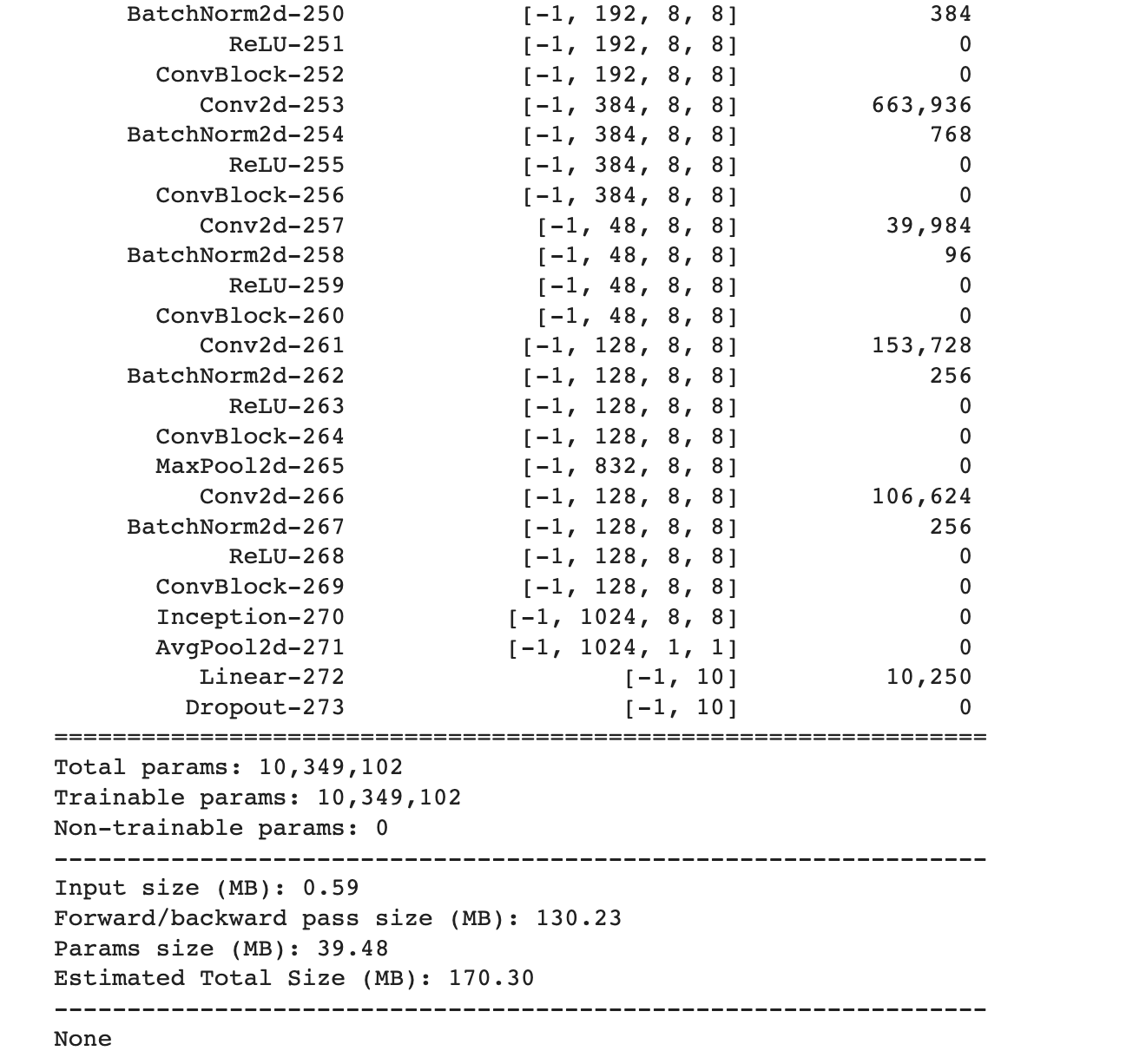
Loss and Optimizer
use_cuda = torch.cuda.is_available()
print("use_cuda : ", use_cuda)
device = torch.device("cuda:0" if use_cuda else "cpu")
model = GoogLeNet().to(device)
criterion = F.cross_entropy
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)Training Loop
writer = SummaryWriter("./googlenet/tensorboard")
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data,target) in enumerate(train_loader):
target = target.type(torch.LongTensor)
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
if model.aux_logits:
loss0 = criterion(output[0], target)
loss1 = criterion(output[1], target)
loss2 = criterion(output[2], target)
loss = loss0 + (0.3 * loss1) + (0.3 * loss2)
else:
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 30 == 0:
print(f"{batch_idx*len(data)}/{len(train_loader.dataset)}")
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target, reduction='mean').item()
writer.add_scalar("Test Loss", test_loss, epoch)
pred = output.argmax(1)
correct += float((pred == target).sum())
writer.add_scalar("Test Accuracy", correct, epoch)
test_loss /= len(test_loader.dataset)
correct /= len(test_loader.dataset)
return test_loss, correct
writer.close()Per-Epoch Activity
for epoch in tqdm(range(1, num_epochs + 1)):
train(model, device, trainloader, optimizer, epoch)
test_loss, test_accuracy = test(model, device, testloader)
writer.add_scalar("Test Loss", test_loss, epoch)
writer.add_scalar("Test Accuracy", test_accuracy, epoch)
print(f"Processing Result = Epoch : {epoch} Loss : {test_loss} Accuracy : {test_accuracy}")
writer.close()
Result
print(f" Result of ResNet = Epoch : {epoch} Loss : {test_loss} Accuracy : {test_accuracy}")
Visualization
%load_ext tensorboard
%tensorboard --logdir=./alexnet/tensorboard --port=6006

728x90
반응형