2023.02.07 - [Project] - [1차] 전국 주유소 현황 분석 (1)
[1차] 전국 주유소 현황 분석 (1)
Python 프로그래밍 기초와 데이터 수집 및 시각화 과목을 들은 후 1차 프로젝트를 진행했다. 강사님 임의로 정한 팀원들과 주제를 선정하는 과정에서 의견이 맞지 않았다. 좋은게 좋은거라 생각하
zzgrworkspace.tistory.com
이전 포스트에서 데이터 수집과 Pandas를 이용해 간단하게 데이터프레임 형태로 저장하는 과정을 보았다. 데이터프레임 형태의 데이터를 시각화하기 위해서 Seaborn, Matplotlib을 기본적으로 사용하였고 추가적으로 Folium을 이용해 주유소 위치를 지도에 표시해 보았다.
# 지역에 따른 브랜드별 주유소 수
# 주소 칼럼을 count 용도로 사용하였다.
regionalbrandcount = df.groupby(['지역','상표'])['주소'].count().reset_index()
sns.catplot(data=regionalbrandcount, x='상표',y='주소',col='지역',col_wrap=3, kind='bar')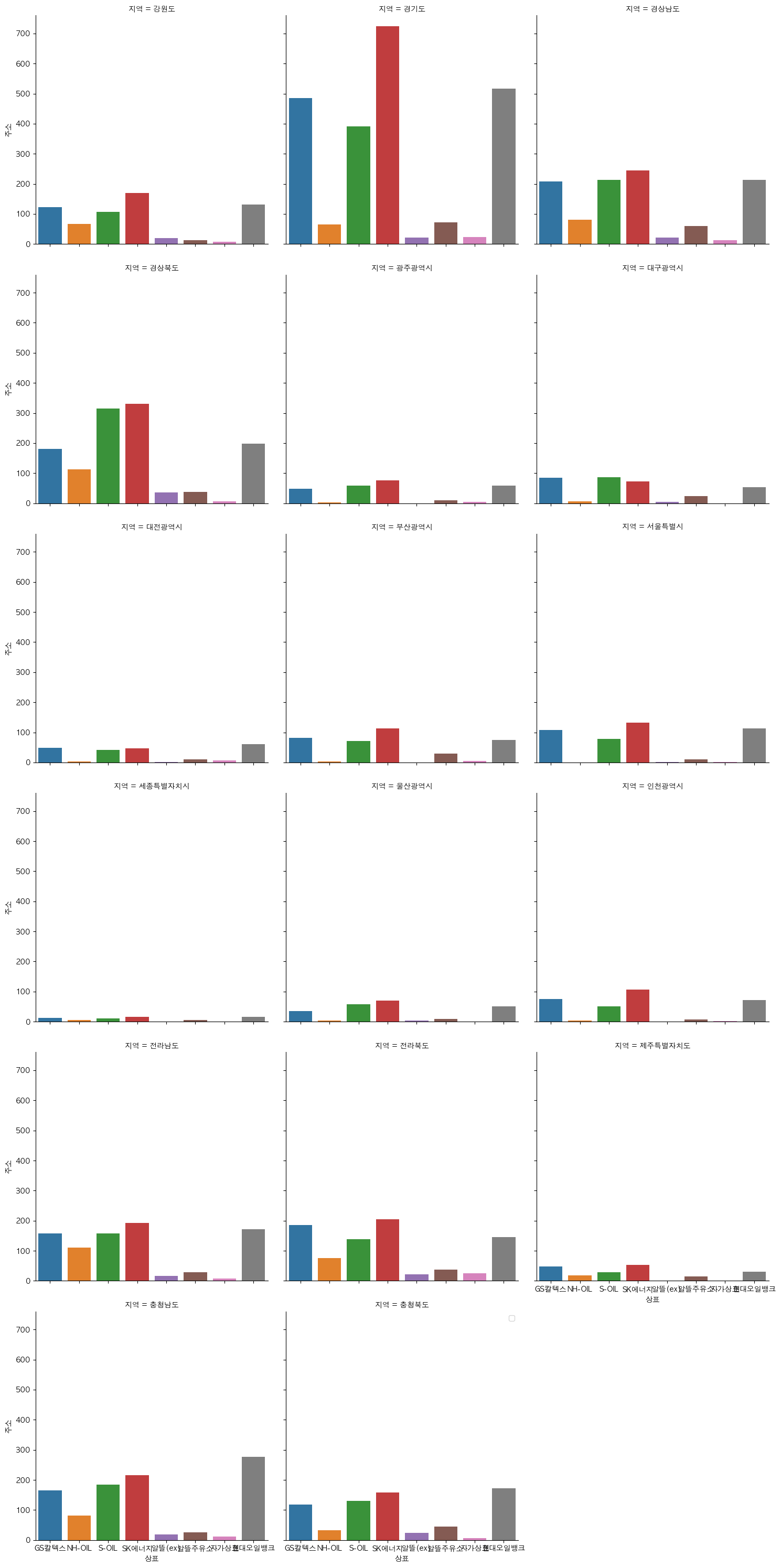
지역에 따른 브랜드별 주유소 개수를 시각화 해보았다. col_wrap 파라미터를 이용해 한 줄에 3개의 그래프씩 나타나도록 설정했다. 그런데 축에 나오는 글씨들이 밀려서 제대로 나오지 않았다. constrained_layout=Ture 을 이용해 서브플롯간의 간격을 가능한 최적의 수치로 자동 조정해 줄 수 있다. 위와 같은 방식으로 셀프여부별, 시군구별, 연도별로 유가 정보에 차이가 있는지 확인해보았다.
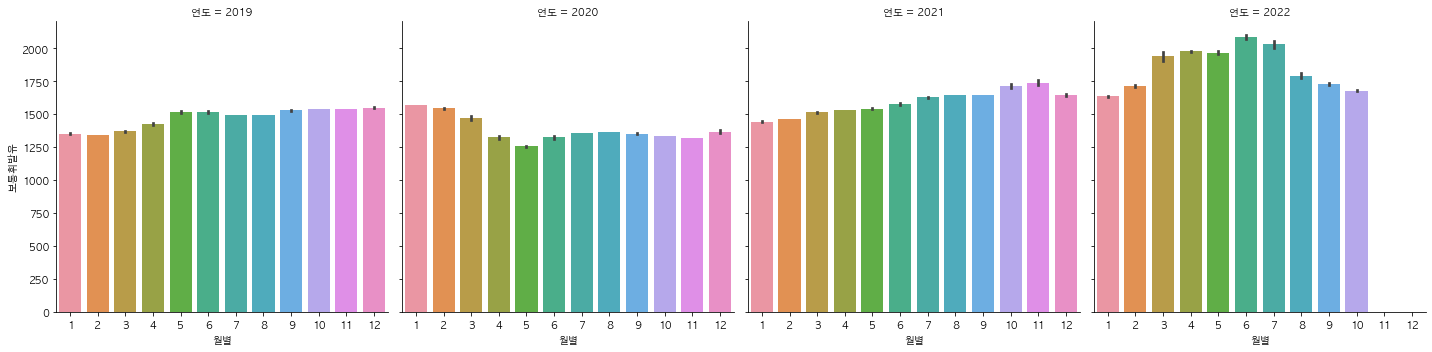
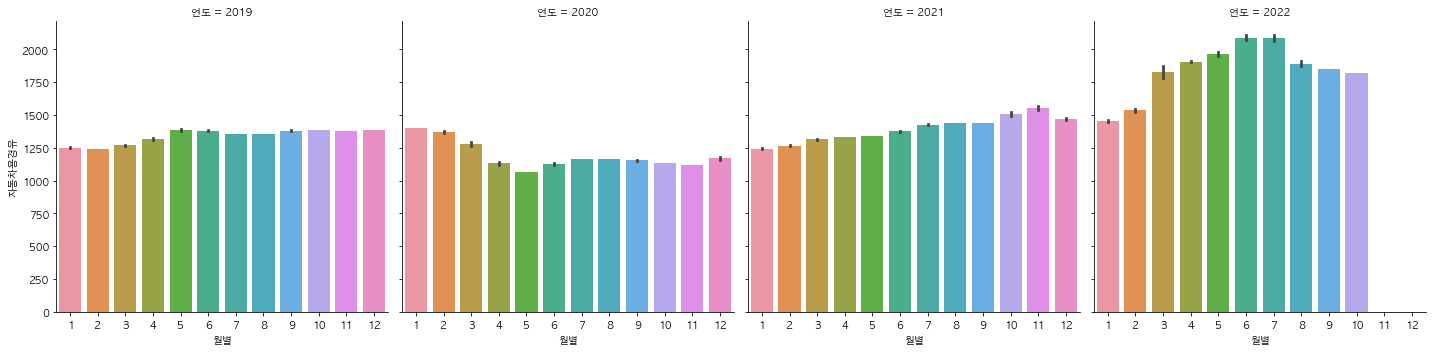
시각화를 하면서 유가의 상승과 하락에 어떤 이유가 있는지 조사해봐야겠다고 생각했다. 그래서 국제적인 이슈로 인해 유가가 변동한다는 가설을 세우고 2019년부터 2022년까지의 네이버 뉴스에 가장 많이 등장한 단어를 수집해 보았다. 네이버 API를 이용하여 크롤링을 진행하였다.
def getPostData(post, jsonResult, cnt):
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
pDate = datetime.datetime.strptime(post['pubDate'],'%a, %d %b %Y %H:%M:%S +0900' )
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S')
jsonResult.append({
'cnt':cnt, 'title':title, 'description':description
,'org_link':org_link, 'link':link, 'pDate':pDate
})
return
def getNaverSearch(node,srcText, start, display):
base = "https://openapi.naver.com/v1/search"
node = "/" + node + ".json"
parameters = f"?query={urllib.parse.quote(srcText)}&start={start}&display={display}"
url = base + node + parameters
responseDecode = getRequestUrl(url)
if(responseDecode == None):
return None
else:
return json.loads(responseDecode)
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id",'nUh0vBVNekTinKV826d_')
req.add_header("X-Naver-Client-Secret",'HVD5Up28ht')
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print(f"{datetime.datetime.now} url request success")
return response.read().decode('utf-8')
except Exception as e:
print(e)
print(f"{datetime.datetime.now} error for url : {url}")
def main():
node = 'news' # target
srcText = input('검색어를 입력하세요')
cnt = 0
jsonResult = []
jsonResponse = getNaverSearch(node, srcText, 1, 100) # start=1, display=100
total = jsonResponse['total']
while( (jsonResponse != None) and (jsonResponse['display'] != 0) ):
for post in jsonResponse['items']:
cnt += 1
getPostData(post,jsonResult,cnt)
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100)
filename = 'crawling_api_result.json'
with open(filename, 'w', encoding='utf-8') as f:
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
f.write(jsonFile)
print(f'전체 검색: {total}건')
print(f'가져온 데이터: {cnt}건')https://changsroad.tistory.com/206?category=549645
[파이썬 빅데이터 분석] 네이버 API를 이용한 크롤링
1. 크롤링이란 웹에서 데이터를 수집하는 기술에는 스크레이핑, 크롤링 이렇게 두가지가 존재한다. 두개를 구분하자면 스크레이핑은 웹에서 특정데이터를 수집하는 것이고, 크롤링은 프로그램
changsroad.tistory.com
코드는 위 changsroad님의 포스트를 참고하여 작성하였다. json 파일 형태로 크롤링한 데이터를 저장한 뒤, Pandas를 이용하여 데이터프레임 형태로 만들고 re.sub()를 이용하여 특수문자를 제거하였다.
with open('/Users/zzgr/Desktop/zzgrSandaeteuk/PROJECT GAS STATION/api_result.json') as f:
raw = json.load(f)
data = pd.DataFrame(raw)
title = [re.sub(r"[^\uAC00-\uD7A30-9·.↓]".strip(), " ", data['title'][i]) for i in range(1000)]
words = [ ]
for i in data['title']:
WordsToken = word_tokenize(Words)
WordsTokenStop = [j for j in WordsToken]
WordsTokenStopLemma = [lemma.lemmatize(j) for j in WordsTokenStop]
words.append(WordsTokenStopLemma)
중복되는 기사 제목이 있어서 크롤링을 잘못했나 싶었는데, 그냥 기레기들이 기사 제목까지 복붙해서 게시해서 저렇게 결과가 나온 것이었다. 리스트에 단어를 저장하고 수를 세보기로 했다. 물론 허수가 있긴 하겠지만 대략적인 추이 정도는 확인이 가능할 것이라고 생각했다.
wordslist = reduce(lambda x,y : x+y, words)
cnt = Counter(wordslist)
cnt.most_common(100)
결과적으로 가설은 증명하지 못했지만, 알뜰주유소라는 키워드가 눈에 띄었다. 이어서 새로운 가설을 만들기 위해 알뜰주유소에 대해 조사를 해보기로 하였다.
'📂 프로젝트 > ◾ 국비지원 1차' 카테고리의 다른 글
| [1차 프로젝트] 전국 주유소 현황 분석 (3) (개발자 취업코스, 국비 지원, 데이터 다루기) (0) | 2023.02.07 |
|---|---|
| [1차 프로젝트] 전국 주유소 현황 분석 (1) (개발자 취업코스, 국비 지원, 데이터 다루기) (0) | 2023.02.07 |


댓글