[배경]
4차 산업혁명 시대를 맞아 농업 분야에서도 인공지능(AI) 기술이 널리 사용되어 IT 기술을 동원한 스마트팜 등 보다 효율적인 작물 재배가 가능해지고 있습니다.
KIST 강릉 분원은 인공지능을 활용하여 국내에서 생장하는 식물 자원 중 유용한 소재를 탐색하고, 그 효능과 활용법에 대해 연구하고 있습니다.
이번 경진대회를 통해 작물의 수확량을 최고로 끌어올릴 수 있는 시간대별 최적 환경을 알아낼 수 있다면, 식물 재배와 관련한 제반 산업에 큰 도움이 될 것입니다.
[주제]
생육 환경 생성 AI 모델 결과를 바탕으로 상추의 일별 최대 잎 중량을 도출할 수 있는 최적의 생육 환경 조성
[설명]
이번 경진대회에서는 예측 모델과 생성 모델 2가지 모두 개발해야 합니다.
- 상추의 일별 잎중량을 예측하는 AI 예측 모델 개발 (정량평가)
- 1번의 예측 모델을 활용하여 생육 환경 생성 AI 모델 개발 (정성평가)
- 생성 AI 모델 결과로부터 상추의 일별 최대 잎 중량을 도출할 수 있는 최적의 생육 환경 조성 및 제안 (최종 결과물)
[주최 / 주관]
- 주최: KIST 강릉분원
- 주관: 데이콘
[결과]

[코드]
Import
# Import Modules
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
import time
import os
import cv2
import random
import math
import glob
from tqdm import tqdm
import re
import seaborn as sns
# Tensorflow
import tensorflow as tf
from tensorflow import keras
from keras.models import Model
from keras.models import Sequential
from keras.layers import Dense, Input, Dropout, Flatten, Conv2D, MaxPool2D, LSTM, Activation, AveragePooling2D
from keras.optimizers import Adam, RMSprop
from keras.losses import categorical_crossentropy
from keras import layers, regularizers,activations
from keras.utils import to_categorical,Sequence
from keras import optimizers, initializers, regularizers, metrics
# sklearn
from sklearn import svm
from sklearn.preprocessing import StandardScaler, RobustScaler, MinMaxScaler
from sklearn.metrics import auc
from sklearn.metrics import RocCurveDisplay
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import precision_score, recall_score, f1_score
from sklearn.linear_model import LinearRegression, Ridge, Lasso
import warnings
warnings.filterwarnings(action='ignore')Hyperparameters
# set hyper parmeters
hyper_param = {
'EPOCHS':500,
'LEARNING_RATE':1e-2,
'BATCH_SIZE':24,
'SEED':2022
}Data Load / Preprocessing
# train data into list
all_input_list = sorted(glob.glob('./data/train_input/*.csv'))
all_target_list = sorted(glob.glob('./data/train_target/*.csv'))
len(all_input_list), len(all_target_list)
# split data - training(21) : validation(7)
train_input_list = all_input_list[:21]
train_target_list = all_target_list[:21]
val_input_list = all_input_list[21:]
val_target_list = all_target_list[21:]
print(f'training: {len(train_input_list)}, validation: {len(val_input_list)}')for input_path, target_path in tqdm(zip(train_input_list, train_target_list)):
input_df = pd.read_csv(input_path)
target_df = pd.read_csv(target_path)EDA

CFG
CFG = {
'EPOCHS':20,
'LEARNING_RATE':1e-3,
'BATCH_SIZE':32,
'SEED':2023}DataLoader
# make custom dataset using Sequence
class Dataloader(tf.keras.utils.Sequence):
def __init__(self, input_paths, target_paths, batch_size, infer_mode, shuffle=False):
self.input_paths = input_paths
self.target_paths = target_paths
self.batch_size = batch_size
self.infer_mode = infer_mode
self.shuffle = shuffle
self.data_list = []
self.label_list = []
print('Data Pre-processing..')
for input_path, target_path in tqdm(zip(self.input_paths, self.target_paths)):
input_df = pd.read_csv(input_path)
target_df = pd.read_csv(target_path)
input_df = input_df.drop(columns=['obs_time'])
input_df = input_df.fillna(0)
target_length = int(len(target_df))
for idx in range(target_length):
time_series = input_df[24*idx:24*(idx+1)].values
self.data_list.append(time_series)
for label in target_df['predicted_weight_g']:
self.label_list.append(label)
print('Done. \n')
self.on_epoch_end()
def __len__(self):
return math.ceil(len(self.data_list)/self.batch_size)
def __getitem__(self, idx):
global data_GAN
indices = self.indices[idx*self.batch_size:(idx+1)*self.batch_size]
data = [self.data_list[i] for i in indices]
label = [self.label_list[i] for i in indices]
data_GAN = data
if self.infer_mode == False:
return tf.convert_to_tensor(data), tf.convert_to_tensor(label)
else:
return tf.convert_to_tensor(data)
def on_epoch_end(self):
self.indices = np.arange(len(self.data_list))
if self.shuffle == True:
np.random.shuffle(self.indices)
train_loader = Dataloader(train_input_list, train_target_list, CFG['BATCH_SIZE'], False, shuffle=False)
val_loader = Dataloader(val_input_list, val_target_list, CFG['BATCH_SIZE'], False, shuffle=False)Modeling
class BaseModel(tf.keras.Model):
def __init__(self):
super(BaseModel, self).__init__()
self.lstm = tf.keras.layers.Bidirectional(LSTM(1028))
self.dropout = tf.keras.layers.Dropout(0.5)
self.lstm = tf.keras.layers.Bidirectional(LSTM(1028))
self.dropout = tf.keras.layers.Dropout(0.5)
self.lstm = tf.keras.layers.Bidirectional(LSTM(1028))
self.dropout = tf.keras.layers.Dropout(0.5)
self.classifier = tf.keras.layers.Dense(1)
def call(self, inputs):
h = self.lstm(inputs)
return self.classifier(h)Compile
model = BaseModel()
model.compile(
optimizer=tf.keras.optimizers.RMSprop(learning_rate=hyper_param['LEARNING_RATE']),
loss=tf.keras.losses.MeanAbsoluteError(), metrics = tf.keras.metrics.RootMeanSquaredError(name='root_mean_squared_error'))
callbacks=[tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=10, min_lr=1e-8)]Train
history = model.fit(
train_loader, validation_data=val_loader,
epochs=hyper_param['EPOCHS'],
callbacks= callbacks)Evaluate
history = model.fit(
train_loader, validation_data=val_loader,
epochs=hyper_param['EPOCHS'],
callbacks= callbacks)
model.evaluate(train_loader), model.evaluate(val_loader)
Visualize
plt.style.use('fivethirtyeight')
plt.plot(history.history['root_mean_squared_error'],label='root_mean_squared_error')
plt.plot(history.history['val_root_mean_squared_error'],label='val_root_mean_squared_error')
plt.title('LSTM RMSE,Val_RMSE')
plt.legend()
plt.show()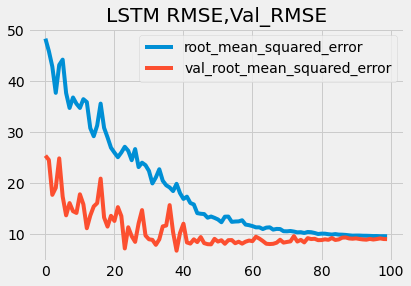
Submission
# test data into list
test_input_list = sorted(glob.glob('/content/drive/MyDrive/lettuce_ori/test_input/*.csv'))
test_target_list = sorted(glob.glob('/content/drive/MyDrive/lettuce_ori/test_target/*.csv'))
len(test_input_list), len(test_target_list)
# test data preprocessing, prediction
for test_input_path, test_target_path in zip(test_input_list, test_target_list):
print(test_target_path)
test_loader = Dataloader([test_input_path], [test_target_path], hyper_param['BATCH_SIZE'], True, shuffle=False)
model_pred = model.predict(test_loader)
submit_df = pd.read_csv(test_target_path)
submit_df['predicted_weight_g'] = model_pred
submit_df.to_csv(test_target_path, index=False)[후기]
간단한 시계열 데이터에 대한 학습은 강의 시간에 해본 적 있지만 정제되지 않은 데이터는 처음 만져봤다. 이상치도 있고, 데이터 양도 적고, EDA를 봐도 뭘 어떻게 손봐야할지 감이 안잡혔다. 모델링과 하이퍼 파라미터에 많은 시간을 써서 좋은 성능을 내는 모델을 만들었지만, 상위권 팀에는 비비지 못할 수준이었다. 그 당시에는 6위여서 1차 합격일 줄 알았다. 그래서 2차 과제인 생성 모델에서 승부수를 내기 위해 GAN 모델을 공부하고 적용해보고 있었다. 그런데 Private 18등까지 떨어지면서 GAN은 무슨 ... 허무하게 끝이 났다.
대회가 끝나고 상위권 팀들의 코드를 보며 복기해봤다. 우선 데이터 전처리에 너무도 무심했다. 최강상추 팀의 경우엔 상관관계를 따져 누적 칼럼들을 모두 삭제했고, 관련도 있는 칼럼들을 통해 새로운 칼럼을 만들었다.

새로운 칼럼들의 왜곡도를 조사하여 로그화를 진행하였고, LGBM 모델로 학습시켰다. 케이스 별로 예측을 진행하였고 조사한 왜곡도 피쳐를 그대로 적용하였다.
머신러닝/ 딥러닝에서 제일 중요한 건 데이터 전처리라는 걸 깨달았다. 더불어 피쳐간 상관관계를 통해 새로운 칼럼을 만들어내거나 삭제함으로써 성능을 향상시킬수 있다는 점을 알게되었다. 그리고 GAN에 대한 내용은 더 많은 공부가 필요하다고 느꼈다. 김칫국 마시며 준비할 때 실패의 연속이었다. G 모델과 D 모델을 통해 학습시켜 새로운 데이터를 생성한다는 아웃라인 정도만 이해했다. 앞으로 포스팅 할 내용 중 하나는 필시 GAN...
'📂 프로젝트 > ◾ DACON' 카테고리의 다른 글
| [데이콘/DACON] 유전체 정보 품종 분류 AI 경진대회 (낯선 데이터 다루기, 데이터 전처리, EDA, StratifiedShuffleSplit, Optuna, Soft Voting) (0) | 2023.02.08 |
|---|

댓글